搜索到
54
篇与
的结果
-
 win10本机安装rabbitMQ 在win10环境下安装RabbitMQ的步骤第一步:下载并安装erlang原因:RabbitMQ服务端代码是使用并发式语言Erlang编写的,安装Rabbit MQ的前提是安装Erlang。下载地址:http://www.erlang.org/downloads由于我的电脑是64位系统,所以我选择是的64位下载。第二步、下载完成后开始安装点击install开始安装,完成后点击close第三步、配置环境变量ERLANG_HOME变量名:ERLANG_HOME变量值就是刚才erlang的安装地址,点击确定。然后双击系统变量path,点击“新建”,将%ERLANG_HOME%\bin加入到path中。最后windows键+R键,输入cmd,再输入erl,看到版本号就说明erlang安装成功了。第四步、下载安装rabbitMq下载地址:http://www.rabbitmq.com/download.html下载完成后双击安装RabbitMQ安装好后接下来安装RabbitMQ-Plugins。打开命令行cd,输入RabbitMQ的sbin目录然后在后面输入rabbitmq-plugins enable rabbitmq_management命令进行安装出现上图代表安装成功,打开sbin目录,双击rabbitmq-server.bat访问 http://localhost:15672默认用户名和密码都是guest登陆即可。原文出处:https://www.cnblogs.com/count-mjb/p/10939117.html
win10本机安装rabbitMQ 在win10环境下安装RabbitMQ的步骤第一步:下载并安装erlang原因:RabbitMQ服务端代码是使用并发式语言Erlang编写的,安装Rabbit MQ的前提是安装Erlang。下载地址:http://www.erlang.org/downloads由于我的电脑是64位系统,所以我选择是的64位下载。第二步、下载完成后开始安装点击install开始安装,完成后点击close第三步、配置环境变量ERLANG_HOME变量名:ERLANG_HOME变量值就是刚才erlang的安装地址,点击确定。然后双击系统变量path,点击“新建”,将%ERLANG_HOME%\bin加入到path中。最后windows键+R键,输入cmd,再输入erl,看到版本号就说明erlang安装成功了。第四步、下载安装rabbitMq下载地址:http://www.rabbitmq.com/download.html下载完成后双击安装RabbitMQ安装好后接下来安装RabbitMQ-Plugins。打开命令行cd,输入RabbitMQ的sbin目录然后在后面输入rabbitmq-plugins enable rabbitmq_management命令进行安装出现上图代表安装成功,打开sbin目录,双击rabbitmq-server.bat访问 http://localhost:15672默认用户名和密码都是guest登陆即可。原文出处:https://www.cnblogs.com/count-mjb/p/10939117.html -
[python] Python日志记录库loguru使用指北 Loguru是一个功能强大且易于使用的开源Python日志记录库。它建立在Python标准库中的logging模块之上,并提供了更加简洁直观、功能丰富的接口。Logging模块的使用见: Python日志记录库logging总结 。Loguru官方仓库见:loguru,loguru官方文档见: loguru-doc。Loguru的主要特点包括:简单易用:无需复杂的配置和定制即可实现基本的日志记录和输出。灵活的日志格式:支持自定义日志格式,并提供丰富的格式化选项。丰富的日志级别:支持多种日志级别,例如DEBUG、INFO、WARNING、ERROR和CRITICAL。多种日志目标:可以将日志输出到终端、文件、电子邮件、网络服务器等目标。强大的日志处理功能:支持日志过滤、格式化、压缩、旋转等功能。支持异步日志记录:能够极大地提升日志记录的性能。支持跨进程、跨线程的日志记录:可以安全地记录多进程、多线程应用程序的日志。Loguru与logging是Python中常用的两个日志记录库,但两者在功能和易用性方面存在一些差异,如下所示:特性Logurulogging易用性更简单易用相对复杂日志格式更灵活较简单日志级别更丰富较少日志目标更多种类较少日志处理功能更强大较弱异步日志记录支持不支持跨进程、跨线程支持支持支持总的来说,loguru在易用性、功能性和性能方面都优于logging。如果要一个简单、强大且易于使用的日志系统,loguru是一个很好的选择。而如果只是需要快速输出一些调试信息,print可能就足够了。不过,对于生产环境,使用loguru或其他日志系统通常会更加合适。Loguru安装命令如下:pip install loguru# 查看loguru版本 import loguru print(loguru.__version__) # 输出:0.7.21 使用说明1.1 基础用法简单使用 Loguru的核心概念是只有一个全局的日志记录器,也就是logger。这个设计使得日志记录变得非常简洁和一致。使用Loguru时,你不需要创建多个日志实例,而是直接使用这个全局的logger来记录信息。这不仅减少了配置的复杂性,也使得日志管理更加集中和高效。from loguru import logger logger.debug("这是一个调试信息")输出:2024-06-29 19:57:44.506 | DEBUG | __main__::3 - 这是一个调试信息Loguru日志输出默认格式如下:时间戳:表示日志记录的具体时间,格式通常为年-月-日 时:分:秒.毫秒。日志级别:表示这条日志的严重性级别。进程或线程标识:表示日志来自哪个模块或脚本。 main 表示日志来自主模块。如果是其他文件会显示文件名。文件名和行号:记录日志消息的函数名和行号。日志消息:实际的日志内容,此外loguru支持使用颜色来区分不同的日志级别,使得日志输出更加直观.日志等级Loguru可以通过简单的函数调用来记录不同级别的日志,并自动处理日志的格式化和输出。这一特点可以让使用者专注于记录重要的信息,而不必关心日志的具体实现细节。Loguru支持的日志级别,按照从最低到最高严重性排序:TRACE: 最详细的日志信息,用于追踪代码执行过程。Loguru默认情况下使用DEBUG级别作为最低日志记录级别,而不是TRACE级别。这是因为TRACE级别会产生大量的日志信息。DEBUG: 用于记录详细的调试信息,通常只在开发过程中使用,以帮助诊断问题。INFO: 用于记录常规信息,比如程序的正常运行状态或一些关键的操作。SUCCESS: 通常用于记录操作成功的消息,比如任务完成或数据成功保存。WARNING: 用于记录可能不是错误,但需要注意或可能在未来导致问题的事件。ERROR: 用于记录错误,这些错误可能会影响程序的某些功能,但通常不会导致程序完全停止。CRITICAL: 用于记录非常严重的错误,这些错误可能会导致程序完全停止或数据丢失。from loguru import logger logger.debug("这是一条跟踪消息") logger.debug("这是一条调试信息") logger.info("这是一条普通信息") logger.success("操作成功完成") logger.warning("这是一条警告信息") logger.error("这是一条错误信息") logger.critical("这是一条严重错误信息")输出:2024-06-29 19:58:11.535 | DEBUG | __main__:<module>:3 - 这是一条跟踪消息 2024-06-29 19:58:11.536 | DEBUG | __main__:<module>:4 - 这是一条调试信息 2024-06-29 19:58:11.536 | INFO | __main__:<module>:5 - 这是一条普通信息 2024-06-29 19:58:11.537 | SUCCESS | __main__:<module>:6 - 操作成功完成 2024-06-29 19:58:11.537 | WARNING | __main__:<module>:7 - 这是一条警告信息 2024-06-29 19:58:11.538 | ERROR | __main__:<module>:8 - 这是一条错误信息 2024-06-29 19:58:11.538 | CRITICAL | __main__:<module>:9 - 这是一条严重错误信息1.2 日志配置在loguru中,add函数用于添加日志处理器。这个函数用于指定日志消息应该被发送到何处,例如控制台、文件或其他自定义的目的地。add函数主要参数介绍如下:sink: 定义日志消息的输出位置,可以是文件路径、标准输出(stdout)、标准错误(stderr,默认)或其他自定义的输出位置。format: 指定日志消息的格式,可以是简单的字符串,也可以是格式化字符串,支持各种字段插值。level: 设置处理程序处理的日志消息的最低级别。比如设置为DEBUG,则处理程序将处理所有级别的日志消息。filter: 可选参数,用于添加过滤器,根据特定的条件过滤掉不需要的日志消息。colorize: 布尔值,指定是否对日志消息进行着色处理,使日志在控制台中更易于区分。serialize: 布尔值,指定是否对日志消息进行序列化处理,通常与enqueue=True一起使用,以确保多线程安全。enqueue: 布尔值,指定是否将日志消息放入队列中处理,用于多线程应用中避免阻塞。backtrace: 布尔值或字符串,指定是否记录回溯信息,默认为False。diagnose: 布尔值,启用后,会在处理程序内部出现错误时记录诊断信息。rotation: 日志文件轮换的配置,支持按大小或时间进行日志文件的轮换。retention: 用于设置日志文件的保留时间。compression: 布尔值,指定是否对轮换后的日志文件进行压缩处理。from loguru import logger import sys # 终端显示不受该段代码设置 # 添加一个日志处理器,输出到文件 # 设置日志最低显示级别为INFO,format将设置sink中的内容 # sink链接的本地文件,如不存在则新建。如果存在则追写 logger.add(sink="myapp.log", level="INFO", format="{time:HH:mm:ss} | {message}| {level}") # debug结果不被显示到本地文件 logger.debug("这是一条调试信息") logger.info("这是一条普通信息")输出:2024-06-29 19:58:56.159 | DEBUG | __main__:<module>:11 - 这是一条调试信息 2024-06-29 19:58:56.159 | INFO | __main__:<module>:12 - 这是一条普通信息当连续两次调用 add 函数时,loguru 会将新的日志处理器添加到处理器列表中,而不是覆盖之前的处理器。这意味着所有添加的处理器都会接收到日志消息,并且按照它们被添加的顺序来处理这些消息。from loguru import logger logger.add(sink="myapp1.log", level="INFO") logger.add(sink="myapp2.log", level="INFO") # 会同时存入所有add添加日志处理器 logger.info("这是一条普通信息,存入myapp2")如果想删除所有已添加的日志处理器,loguru运行使用 logger.remove()方法不带任何参数来移除所有日志处理器。from loguru import logger import sys # 移除所有日志处理器(包括终端输出) logger.remove() logger.add(sink="myapp3.log", level="INFO", format="{time:HH:mm:ss} | {message}| {level}") logger.debug("这是一条调试信息存入myapp3") logger.info("这是一条普通信息存入myapp3")注意调用logger.remove()之后的所有日志将不会被记录,因为没有处理器了。from loguru import logger # 移除所有日志处理器(包括终端输出) logger.remove() # 没有输出 logger.info("这是一条普通信息存入myapp3")如果希望移除某些日志处理器,而不是从所有日志器中移除,代码如下:from loguru import logger # 移除默认终端logger,如果终端存在。 # logger.remove(0) # 添加多个文件处理器,enqueu设置异步日志记录 handler1 = logger.add("myapp1.log", enqueue=True) print(handler1) # handler_id是移除的处理器的唯一标识符 handler2 = logger.add("myapp2.log") # 记录一些日志 logger.info("这些信息会被记录到两个文件中") # 移除特定的文件处理器 logger.remove(handler1) # 现在只有myapp2.log 会记录日志 logger.info("这条信息只会记录在myapp2.log 中")如果想将日志输出到日志台,代码如下:from loguru import logger import sys logger.remove() # 移除默认输出 # 添加一个日志处理器,输出到控制台,使用自定义格式 logger.add( sink=sys.stdout, level="DEBUG", # green表示颜色 format="<green>{time:HH:mm}</green> <level>{message}</level>" ) # 注意终端显示会同步显示 logger.debug("这是一条调试信息") logger.info("这是一条普通信息")时间自定义 可以使用datatime库来自定义日志时间格式。from datetime import datetime from loguru import logger # 自定义时间格式 # time_format = "%Y-%m-%d %H:%M:%S,%f" # 包括微秒 time_format = "%H:%M:%S,%f" # 包括微秒但不含年月日 # 定义日志格式,使用 datetime.now().strftime() 来格式化时间 log_format = "{time:" + time_format + "} - {level} - {message}" logger.add("myapp.log", format=log_format, level="DEBUG") # 记录一条日志 logger.debug("这是一个带有微秒的测试日志")日志轮换from loguru import logger # 当文件大小达到100MB时创建新的日志文件,旧文件保留并重命名,用于防止单个日志文件变得过大。 logger.add("file_1.log", rotation="100 MB") # 每天中午12时创建新的日志文件,旧文件保留并重命名 logger.add("file_2.log", rotation="12:00") # 当日志文件存在超过一周时创建新的日志文件,旧文件保留并重命名 logger.add("file_3.log", rotation="1 week") # 设置日志文件保留10天 logger.add("file_4.log", retention="10 days") # 当文件大小达到100MB时创建新的日志文件,旧文件保留压缩为zip文件 logger.add('file_{time}.log', rotation="100 MB", compression='zip')1.3 进阶使用异常捕获 @logger.catch装饰器可以用来装饰my_function函数,并将这些异常信息记录到日志中。from loguru import logger logger.add(sink='myapp.log') @logger.catch def my_function(x, y): return x / y res = my_function(0,0)过滤 使用loguru库进行Python日志记录时,可以通过自定义的filter函数来筛选并记录特定的日志信息。此函数接收一个记录对象作为参数,根据日志消息内容(message)、级别(level)或其他日志属性,返回布尔值以决定是否记录该条日志。如果函数返回True,则日志被记录;若返回False,则忽略该日志。from loguru import logger # 定义一个过滤器函数 def my_filter(record): # 只记录包含 "第一" 的日志 return "第一" in record["message"] # 使用过滤器 logger.add("myapp.log", filter=my_filter) # 记录一些日志 logger.info("第一个记录") logger.info("第二个记录")此外可以结合bind方法进行过滤,bind方法用于向日志记录器添加额外的上下文信息。这些信息将被包含在每条日志消息中,但不会改变日志消息本身。如下所示:from loguru import logger def filter_user(record): return record["extra"].get("user") =="A" logger.add("myapp.log", filter=filter_user) # 绑定user logger.bind(user="A").info("来自A") logger.bind(user="B").info("来自B")原文出处:https://www.cnblogs.com/luohenyueji/p/18276299
-
SQLAlchemy之一对多关系 1.创建单表class Test(Base): __tablename__ = 'user' nid = Colume(Integer,primary_key=True,autoincrement=True) name = Colume(String(32))2.创建一对多class Team(Base): __tablename__ = 'team' tid = Colume(Integer,primary_key=True,autoincrement=True) caption = Colume(String(32)) class user(Base): __tablename__ = 'user' nid = Colume(Integer,primary_key=True,autoincrement=True) name = Colume(String(32)) team_id = Colume(Integer,ForeignKey('team.gid'))写完类,接下来就是把类转化为数据库表了。3.生成表、删除表def init_db(): #根据Base去找它的子类,把所有的子类生成表。 Base.metadata.create_all(engine) def drop_db(): #把Base所有的子类对应表删除。 Base.metadata.drop_all(engine)from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://python:python@192.168.0.57:3306/python_mysql", max_overflow=5) Base = declarative_base() # 单表 class Test(Base): __tablename__ = 'test' nid = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(32)) # 一对多 class Team(Base): __tablename__ = 'team' tid = Column(Integer, primary_key=True, autoincrement=True) caption = Column(String(32)) class user(Base): __tablename__ = 'user' nid = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(32)) team_id = Column(Integer, ForeignKey('team.tid')) def init_db(): Base.metadata.create_all(engine) def drop_db(): Base.metadata.drop_all(engine) init_db()执行完上面代码后,就会在对应库生成test、user、group三张表,user表的group_id以group表的gid为外键。4.生成表后开始操作表,添加team表数据from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://python:python@192.168.0.57:3306/python_mysql", max_overflow=5) Base = declarative_base() # 单表 class Test(Base): __tablename__ = 'test' nid = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(32)) # 一对多 class Team(Base): __tablename__ = 'team' tid = Column(Integer, primary_key=True, autoincrement=True) caption = Column(String(32)) class user(Base): __tablename__ = 'user' nid = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(32)) team_id = Column(Integer, ForeignKey('team.tid')) def init_db(): Base.metadata.create_all(engine) def drop_db(): Base.metadata.drop_all(engine) # init_db() # drop_db() Session = sessionmaker(bind=engine) session = Session() #往team表里插入两条数据 session.add(Team(caption='dba')) session.add(Team(caption='ddd')) session.commit()5. 添加user表数据Session = sessionmaker(bind=engine) session = Session() #批量添加数据;user表的team_id与team表的tid是有外键的,按理来说要插入的team_id的值必须在team表里有对应的tid值,比如这里插入的tead_id是1、2、3,则team表里的tid至少要有1、2、3,不然会插入失败。 #但是,我发现插入没有对应键值的team_id也不会报错。 session.add_all([ User(name='zzz',team_id=1), User(name='sss',team_id=2), User(name='ccc',team_id=3), ]) session.commit()6.查询单表如果仅仅是查询user表的name值,那不需要联合别的表,直接查询单表即可ret = session.query(User).filter(User.name=='zzz').all() obj = ret[0] print(obj.name) #上面的代码等价于这个: ret = session.query(User.name).filter(User.name=='zzz').all() print(ret)7.通过__repr__()方法改变返回值from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://python:python@192.168.0.57:3306/python_mysql", max_overflow=5) Base = declarative_base() # 创建单表 class Users(Base): __tablename__ = 'users' id = Column(Integer, primary_key=True) name = Column(String(32)) extra = Column(String(16)) __table_args__ = ( UniqueConstraint('id', 'name', name='uix_id_name'), Index('ix_id_name', 'name', 'extra'), ) #__repr__方法是注释的,看print(ret)的输出 #def __repr__(self): # return "%s-%s" %(self.id, self.name) def init_db(): Base.metadata.create_all(engine) def drop_db(): Base.metadata.drop_all(engine) init_db() Session = sessionmaker(bind=engine) session = Session() session.add(Users(id=1,name='zsc')) session.commit() ret = session.query(Users).all() print(ret) #结果: [<__main__.Users object at 0x7f1836e80630>] 没有User类里没有__repr__方法时,session.query(Users).all()返回的是类的对象。from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://python:python@192.168.0.57:3306/python_mysql", max_overflow=5) Base = declarative_base() # 创建单表 class Users(Base): __tablename__ = 'users' id = Column(Integer, primary_key=True) name = Column(String(32)) extra = Column(String(16)) __table_args__ = ( UniqueConstraint('id', 'name', name='uix_id_name'), Index('ix_id_name', 'name', 'extra'), ) #__repr__方法取消注释 def __repr__(self): return "%s-%s" %(self.id, self.name) def init_db(): Base.metadata.create_all(engine) def drop_db(): Base.metadata.drop_all(engine) init_db() Session = sessionmaker(bind=engine) session = Session() session.add(Users(id=1,name='zsc')) session.commit() ret = session.query(Users).all() print(ret) #结果: [1-zsc] User类里定义了__repr__方法时,session.query(Users).all()返回的是定义的返回结果。8.联合查询#创建表时指定了外键 ret = session.query(User.name).join(Team).all()等价于SELECT user.name AS FROM user INNER JOIN team ON team.tid = user.team_id #用select的话需要用on指定约束条件,用SQLAlchemy就不用指定了。 #用“isouter=True”指定left join ret = session.query(User.name).join(Team,isouter=True).all()上面的查询,随便是依赖到了别的表,但是结果只是显示了user表的数据,如果想同时显示user和team表的数据,就得用下面的方法了,ret = session.query(User.name,Team.caption).join(Team).all() print(ret) #结果: [('zzz', 'dba'), ('sss', 'ddd')]虽然上面的联合查询已经比直接用select简单了,但是还是很麻烦,所以就有了下面的方法。9.relationship9.1 利用ralationship正向查询正向查询即是使用做外链的表来查询被外链里的数据from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://python:python@192.168.0.57:3306/python_mysql", max_overflow=5) Base = declarative_base() # 一对多 class Team(Base): __tablename__ = 'team' tid = Column(Integer, primary_key=True, autoincrement=True) caption = Column(String(32)) class User(Base): __tablename__ = 'user' nid = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(32)) team_id = Column(Integer, ForeignKey('team.tid')) #加上底下这行后,不用使用.join()也可实现联表查询 #哪个表做外链,就把relationship加到哪个表 favor = relationship("Team", backref='uuu') def init_db(): Base.metadata.create_all(engine) def drop_db(): Base.metadata.drop_all(engine) # init_db() # drop_db() Session = sessionmaker(bind=engine) session = Session() ret = session.query(User).all() for obj in ret: print(obj.nid,obj.name,obj.favor,obj.favor.tid,obj.favor.caption) #结果: 1 zzz <__main__.Team object at 0x7f5c10d02a20> 1 dba 2 sss <__main__.Team object at 0x7f5c10d026a0> 2 ddd #可见,ret仅仅是User的query结果,而使用obj.favor就相当于是使用Team表,即可直接操作team表。9.2利用ralationship实现反向查询反向查询即是使用被外链的表查询到做外链的数据class Test(Base): __tablename__ = 'test' nid = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(32)) # 一对多 class Team(Base): __tablename__ = 'team' tid = Column(Integer, primary_key=True, autoincrement=True) caption = Column(String(32)) class User(Base): __tablename__ = 'user' nid = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(32)) team_id = Column(Integer, ForeignKey('team.tid')) favor = relationship("Team", backref='uuu') def init_db(): Base.metadata.create_all(engine) def drop_db(): Base.metadata.drop_all(engine) # init_db() # drop_db() Session = sessionmaker(bind=engine) session = Session() ret = session.query(Team).filter(Team.caption == 'dba').all() print(ret[0].tid) print(ret[0].caption) print(ret[0].uuu) #结果: 1 dba [<__main__.User object at 0x7f7d3fa5ba20>] #favor = relationship("Team", backref='uuu')里的uuu的作用就是存储着对应的做外链里的数据;比如user里有7个人是dba组的,这时候print(ret[0].uuu)就会返回7个用户的信息;user里有3个dbb组的,这时候print(ret[0].uuu)就会返回3个相关用户的信息。除了一对多还是多对多关系,多对多是专门建一个中间表来存储两张表的关联关系。SQLAlchemy看着麻烦,其实就是记语法而已,多用即可;先建表,再操作单表,再用连表,在整关系,一对多,多对多。原文转载:https://www.cnblogs.com/fuckily/p/6042743.html
-
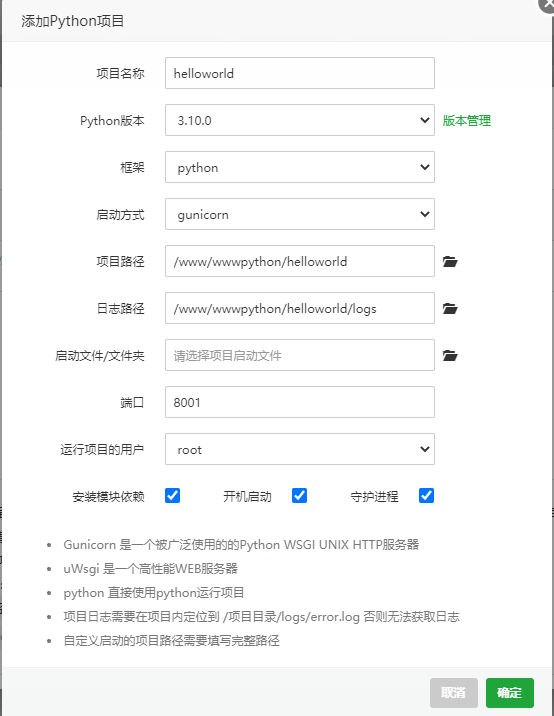
宝塔上部署FastAPI的步骤和一些注意点 {callout color="#999999"}为了运维方便,选择直接用宝塔来管理python fastapi的项目,虽然直接部署可能性能更好更灵活,但是我选择了低层本,每个人的选择可能是不一样的,各有 考虑吧。本文的大逻辑是先写一个helloworld的程序,然后再部署到服务器上{/callout}步骤一:先本地运行一个基于fastapi的helloWorld例子,方便后面在服务器上验证编写基于FastApi的Hello World文件main.pyimport uvicorn from fastapi import FastAPI app = FastAPI() @app.get("/") def sayHi(): return {"message":"Hello world!"} # 启动uvicorn服务,默认端口8000 uvicorn myapi:api --reload if __name__ == '__main__': uvicorn.run('main:app')显示本地运行跑通,本地可以使用vscode编译器,并在运行dos命令pip install fastapi[all] uvicorn main:app --reloadreload参数是为了修改代码后的热部署,运行没有报错后可以浏览器访问: http://127.0.0.1:8000如果看到打印信息则说明OK步骤二:在宝塔上部署python的环境商店安装插件python进程管理插件Python项目管理器:管理应用实例进程守护管理器:实例进程的守护进入Python项目管理器,首先安装python版本,尽量与本地的一致,避免出现本地好的,服务器上出现问题,特别怕依赖包不一致的问题。本地查看版本的命令是python --version在本地生成requirements.txt,否则宝塔创建项目会报错。创建命令如下pip freeze >requirements.txt pip install -r requirements.txt将代码上传到宝塔的/www/wwwpython/helloworld在python进程管理插件创建项目,具体参数如下,记得选择gunicon在配置修改参数,重启。默认为worker_class = 'geventwebsocket.gunicorn.workers.GeventWebSocketWorker' 修改为worker_class = 'uvicorn.workers.UvicornWorker'这里有一个坑,启动后系统会自动暂停,日志报错如下的话,是2个问题,一是启动文件名为main.py,二是启动文件是app,即在main.py中启动命令是:uvicorn.run('main:app')具体报错信息如下:Worker failed to boot.Traceback (most recent call last): File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/arbiter.py", line 586, in spawn_worker worker.init_process() File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/workers/ggevent.py", line 203, in init_process super(GeventWorker, self).init_process() File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/workers/base.py", line 135, in init_process self.load_wsgi() File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/workers/base.py", line 144, in load_wsgi self.wsgi = self.app.wsgi() File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/app/base.py", line 67, in wsgi self.callable = self.load() File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/app/wsgiapp.py", line 52, in load return self.load_wsgiapp() File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/app/wsgiapp.py", line 41, in load_wsgiapp return util.import_app(self.app_uri) File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/util.py", line 350, in import_app __import__(module) File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gevent/builtins.py", line 96, in __import__ result = _import(*args, **kwargs) File "/www/wwwpython/helloworld/myapi.py", line 9 SyntaxError: Non-ASCII character '\xe5' in file /www/wwwpython/helloworld/myapi.py on line 9, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details [2023-03-25 09:26:44 +0000] [7373] [INFO] Worker exiting (pid: 7373) [2023-03-25 09:26:44 +0000] [7368] [INFO] Shutting down: Master [2023-03-25 09:26:44 +0000] [7368] [INFO] Reason: Worker failed to boot. [2023-03-25 09:26:45 +0000] [7385] [INFO] Starting gunicorn 19.10.0 [2023-03-25 09:26:45 +0000] [7385] [INFO] Listening at: http://0.0.0.0:12345 (7385) [2023-03-25 09:26:45 +0000] [7385] [INFO] Using worker: geventwebsocket.gunicorn.workers.GeventWebSocketWorker [2023-03-25 09:26:45 +0000] [7394] [INFO] Booting worker with pid: 7394 [2023-03-25 09:26:45 +0000] [7394] [ERROR] Exception in worker process Traceback (most recent call last): File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/arbiter.py", line 586, in spawn_worker worker.init_process() File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/workers/ggevent.py", line 203, in init_process super(GeventWorker, self).init_process() File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/workers/base.py", line 135, in init_process self.load_wsgi() File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/workers/base.py", line 144, in load_wsgi self.wsgi = self.app.wsgi() File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/app/base.py", line 67, in wsgi self.callable = self.load() File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/app/wsgiapp.py", line 52, in load return self.load_wsgiapp() File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/app/wsgiapp.py", line 41, in load_wsgiapp return util.import_app(self.app_uri) File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gunicorn/util.py", line 350, in import_app __import__(module) File "/www/wwwpython/helloworld/helloworld_venv/lib/python2.7/site-packages/gevent/builtins.py", line 96, in __import__ result = _import(*args, **kwargs) File "/www/wwwpython/helloworld/myapi.py", line 9 SyntaxError: Non-ASCII character '\xe5' in file /www/wwwpython/helloworld/myapi.py on line 9, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details [2023-03-25 09:26:45 +0000] [7394] [INFO] Worker exiting (pid: 7394) [2023-03-25 09:26:45 +0000] [7385] [INFO] Shutting down: Master [2023-03-25 09:26:45 +0000] [7385] [INFO] Reason: Worker failed to boot.设置映射域名,比如设置了 demo.xxx.com,即系统会自动创建这个域名的网站,并设置了反向代理通过 http://demo.xxx.com 返回正常即配置完成。原文出处:https://www.cnblogs.com/jpeanut/p/17254756.html
-
Python 数据结构 逻辑结构特点:只是描述数据结构中数据元素之间的联系规律是从具体问题中抽象出来的数学模型,是独立于计算机存储器的(与机器无关)逻辑结构分类线性结构集合中必存在唯一的一个 "第一个元素"集合中必存在唯一的一个 "最后的元素"除最后元素之外,其他数据元素均有唯一的 "后继"除第一元素之外,其他数据元素均有唯一的 "前驱"树形结构(层次结构)树形结构指的是数据元素之间存在着"一对多"的树形关系的数据结构,是一类重要的非线性数据结构。在树形结构中,树根结点没有前驱结点,其余每个结点有且只有一个前驱结点。叶子结点没有后续结点,其余每个结点的后续节点数可以是一个也可以是多个。图状结构(网状结构)图是一种比较复杂的数据结构。在图结构中任意两个元素之间都可能有关系,也就是说这是一种多对多的关系。其他结构除了以上几种常见的逻辑结构外,数据结构中还包含其他的结构,比如集合等。有时根据实际情况抽象的模型不止是简单的某一种,也可能拥有更多的特征。存储结构特点:是数据的逻辑结构在计算机存储器中的映象(或表示)存储结构是通过计算机程序来实现的,因而是依赖于具体的计算机语言的。存储结构分类顺序存储顺序存储( Sequential Storage ):将数据结构中各元素按照其逻辑顺序存放于存储器一片连续的存储空间中。链式存储链式存储(Linked Storage )∶将数据结构中各元素分布到存储器的不同点,用记录下一个结点位置的方式建立它们之间的联系,由此得到的存储结构为链式存储结构。索引存储索引存储( lndexed Storage ):在存储数据的同时,建立一个附加的索引表,即索引存储结构=数据文件+索引表。线性表的链式存储只能操作头部节点指向下一个定义将线性表L=(a0,a1.......an-1)中各元素分布在存储器的不同存储块,称为结点,每个结点(尾节点除外)中都持有一个指向下一个节 点的引用,这样所得到的存储结构为链表结构。特点逻辑上相邻的元素ai, ai+1,其存储位置也不一定相邻;存储稀疏,不必开辟整块存储空间。对表的插入和删除等运算的效率较高。逻辑结构复杂,不利于遍历。栈先进后出 --> 水桶定义栈是限制在一端进行插入操作和删除操作的线性表(俗称堆栈),允许进行操作的一端称为"栈顶”,另一固定端称为"栈底”,当栈中没有元素时称为空栈"。特点栈只能在一端进行数据操作栈模型具有先进后出或者叫做后进先出的规律队列先进先出 --> 排队定义队列是限制在两端进行插入操作和删除操作的线性表,允许进行存入操作的一端称为队尾”,允许进行删除操作的一健称为“队就-b特点:队列只能在队头和队尾进行数据操作队列模型具有先进先出或者叫做后进后出的规律树形结构定义树( Tree )是n ( n≥0 )个节点的有限集合T,它满足两个条件∶有且仅有一个特定的称为根(Root )的节点;其余的节点可以分为m ( m≥0 )个互不相交的有限集合T1、T2、......、Tm,其中每一个集合又是一棵树,并称为其根的子树( Subtree ) 。基本概念一个节点的子树的个数称为该节点的度数,一棵树的度数是指该树中节点的最大度数。度数为零的节点称为树叶或终端节点,度数不为零的节点称为分支节点,除根节点外的分支节点称为内部节点。一个节点的子树之根节点称为该节点的子节点,该节点称为它们的父节点,同一节点的各个子节点之间称为兄弟节点。一棵树的根节点没有父节点,叶节点没有子节点。一个节点系列k1,k2,......,ki,ki+1,......,kj,并满足ki是ki+1的父节点,就称为一条从k1到kj的路径,路径的长度为j-1,即路径中的边数。路径中前面的节点是后面节点的祖先,后面节点是前面节点的子孙。节点的层数等于父节点的层数加一,根节点的层数定义为树中节点层数的最大值称为该树的高度或深度。m ( m≥0 )棵互不相交的树的集合称为森林。树去掉根节点就成为森林,森林加上一个新的根节点就成为树。二叉树定义二叉树( Binary Tree )是n ( n≥0 )个节点的有限集合,它或者是空集( n=0 ),或者是由一个根节点以及两棵互不相交的、分别称为左子树和右子树的二叉树组成。二叉树与普通有序树不同,二叉树严格区分左孩子和右孩子,即使只有一个子节点也要区分左右。二叉树的特征工叉树第i ( i≥1)层上的节点最多为2i-1个。深度为k ( k≥1)的二叉树最多有2k一1个节点。在任意一棵二叉树中,树叶的数目比度数为2的节点的数目多一。满二叉树︰深度为k ( k≥1)时有2k一1个节点的二叉树。完全二叉树∶只有最下面两层有度数小于2的节点,且最下面一层的叶节点集中在最左边的若干位置上。二叉树的遍历沿某条搜索路径周游二叉树,对树中的每一个节点访问一次且仅访问一次。先序遍历︰先访问树根,再访问左子树,最后访问右子树; --> 根左右中序遍历︰先访问左子树,再访问树根,最后访问右子树; --> 左根右后序遍历︰先访问左子树,再访问右子树,最后访问树根﹔ --> 左右根 层次遍历:从根节点开始,逐层从左向右进行遍历。递归思想什么是递归?所谓递归函数是指一个函数的函数体中直接调用或间接调用了该函数自身的函数。这里的直接调用是指一个函数的函数体中含有调用自身的语句,间接调用是指一个函数在函数体里有调用了其它函数,而其它函数又反过来调用了该函数的情况。 递归函数调用的执行过程分为两个阶段递推阶段︰从原问题出发,按递归公式递推从未知到已知,最终达到递归终止条件。回归阶段:按递归终止条件求出结果,逆向逐步代入递归公式,回归到原问题求解。 优点与缺点优点︰递归可以把问题简单化,让思路更为清晰,代码更简洁缺点︰递归因系统环境影响大,当递归深度太大时,可能会得到不可预知的结果算法基础基础概念特征定义算法( Algorithm )是一个有穷规则(或语句、指令)的有序集合。它确定了解决某一问题的一个运算序列。对于问题的初始输入,通过算法有限步的运行,产生一个或多个输出。数据的逻辑结构与存储结构密切相关算法设计:取决于选定的逻辑结构算法实现:依赖于采用的存储结构算法的特性有穷性—~算法执行的步骤(或规则)是有限的;确定性——每个计算步骤无二义性;可行性——每个计算步骤能够在有限的时间内完成;输入,输出——存在数据的输入和出输出评价算法好坏的方法正确性︰运行正确是一个算法的前提。可读性︰容易理解、容易编程和调试、容易维护。健壮性:考虑情况全面,不容以出现运行错误。时间效率高︰算法消耗的时间少。储存量低︰占用较少的存储空间。排序和查找排序排序(Sort)是将无序的记录序列(或称文件)调整成有序的序列。常见排序方法∶冒泡排序冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。选择排序工作原理为,首先在未排序序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到排序序列末尾。以此类推,直到所有元素均排序完毕
![[python] Python日志记录库loguru使用指北](https://blog.yiyunt.cn/usr/themes/Joe-master/assets/thumb/40.jpg)