搜索到
17
篇与
的结果
-
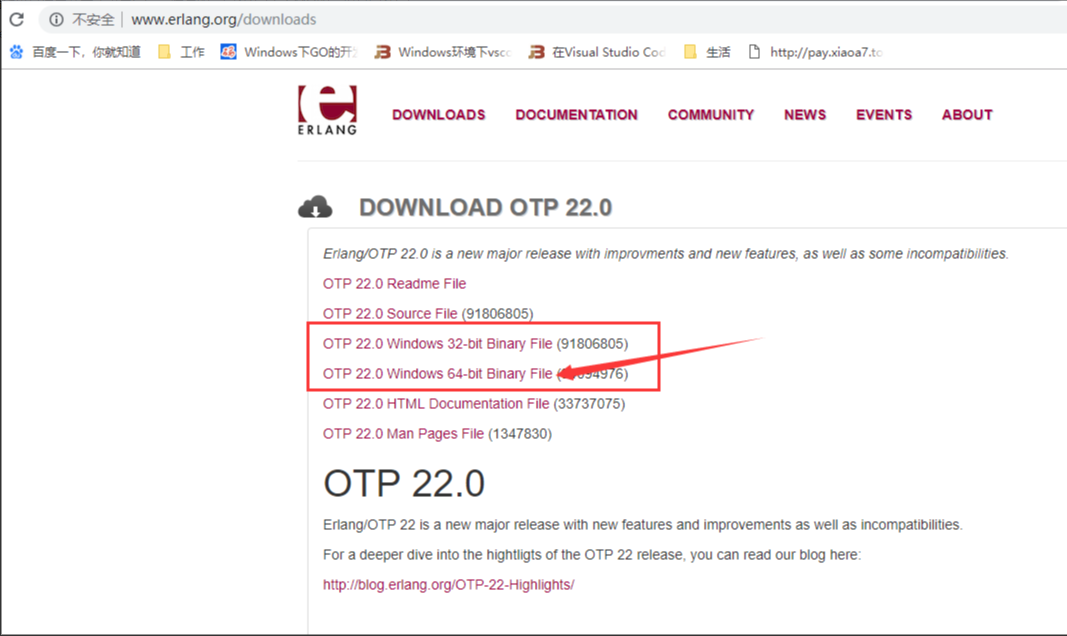
 win10本机安装rabbitMQ 在win10环境下安装RabbitMQ的步骤第一步:下载并安装erlang原因:RabbitMQ服务端代码是使用并发式语言Erlang编写的,安装Rabbit MQ的前提是安装Erlang。下载地址:http://www.erlang.org/downloads由于我的电脑是64位系统,所以我选择是的64位下载。第二步、下载完成后开始安装点击install开始安装,完成后点击close第三步、配置环境变量ERLANG_HOME变量名:ERLANG_HOME变量值就是刚才erlang的安装地址,点击确定。然后双击系统变量path,点击“新建”,将%ERLANG_HOME%\bin加入到path中。最后windows键+R键,输入cmd,再输入erl,看到版本号就说明erlang安装成功了。第四步、下载安装rabbitMq下载地址:http://www.rabbitmq.com/download.html下载完成后双击安装RabbitMQ安装好后接下来安装RabbitMQ-Plugins。打开命令行cd,输入RabbitMQ的sbin目录然后在后面输入rabbitmq-plugins enable rabbitmq_management命令进行安装出现上图代表安装成功,打开sbin目录,双击rabbitmq-server.bat访问 http://localhost:15672默认用户名和密码都是guest登陆即可。原文出处:https://www.cnblogs.com/count-mjb/p/10939117.html
win10本机安装rabbitMQ 在win10环境下安装RabbitMQ的步骤第一步:下载并安装erlang原因:RabbitMQ服务端代码是使用并发式语言Erlang编写的,安装Rabbit MQ的前提是安装Erlang。下载地址:http://www.erlang.org/downloads由于我的电脑是64位系统,所以我选择是的64位下载。第二步、下载完成后开始安装点击install开始安装,完成后点击close第三步、配置环境变量ERLANG_HOME变量名:ERLANG_HOME变量值就是刚才erlang的安装地址,点击确定。然后双击系统变量path,点击“新建”,将%ERLANG_HOME%\bin加入到path中。最后windows键+R键,输入cmd,再输入erl,看到版本号就说明erlang安装成功了。第四步、下载安装rabbitMq下载地址:http://www.rabbitmq.com/download.html下载完成后双击安装RabbitMQ安装好后接下来安装RabbitMQ-Plugins。打开命令行cd,输入RabbitMQ的sbin目录然后在后面输入rabbitmq-plugins enable rabbitmq_management命令进行安装出现上图代表安装成功,打开sbin目录,双击rabbitmq-server.bat访问 http://localhost:15672默认用户名和密码都是guest登陆即可。原文出处:https://www.cnblogs.com/count-mjb/p/10939117.html -
[python] Python日志记录库loguru使用指北 Loguru是一个功能强大且易于使用的开源Python日志记录库。它建立在Python标准库中的logging模块之上,并提供了更加简洁直观、功能丰富的接口。Logging模块的使用见: Python日志记录库logging总结 。Loguru官方仓库见:loguru,loguru官方文档见: loguru-doc。Loguru的主要特点包括:简单易用:无需复杂的配置和定制即可实现基本的日志记录和输出。灵活的日志格式:支持自定义日志格式,并提供丰富的格式化选项。丰富的日志级别:支持多种日志级别,例如DEBUG、INFO、WARNING、ERROR和CRITICAL。多种日志目标:可以将日志输出到终端、文件、电子邮件、网络服务器等目标。强大的日志处理功能:支持日志过滤、格式化、压缩、旋转等功能。支持异步日志记录:能够极大地提升日志记录的性能。支持跨进程、跨线程的日志记录:可以安全地记录多进程、多线程应用程序的日志。Loguru与logging是Python中常用的两个日志记录库,但两者在功能和易用性方面存在一些差异,如下所示:特性Logurulogging易用性更简单易用相对复杂日志格式更灵活较简单日志级别更丰富较少日志目标更多种类较少日志处理功能更强大较弱异步日志记录支持不支持跨进程、跨线程支持支持支持总的来说,loguru在易用性、功能性和性能方面都优于logging。如果要一个简单、强大且易于使用的日志系统,loguru是一个很好的选择。而如果只是需要快速输出一些调试信息,print可能就足够了。不过,对于生产环境,使用loguru或其他日志系统通常会更加合适。Loguru安装命令如下:pip install loguru# 查看loguru版本 import loguru print(loguru.__version__) # 输出:0.7.21 使用说明1.1 基础用法简单使用 Loguru的核心概念是只有一个全局的日志记录器,也就是logger。这个设计使得日志记录变得非常简洁和一致。使用Loguru时,你不需要创建多个日志实例,而是直接使用这个全局的logger来记录信息。这不仅减少了配置的复杂性,也使得日志管理更加集中和高效。from loguru import logger logger.debug("这是一个调试信息")输出:2024-06-29 19:57:44.506 | DEBUG | __main__::3 - 这是一个调试信息Loguru日志输出默认格式如下:时间戳:表示日志记录的具体时间,格式通常为年-月-日 时:分:秒.毫秒。日志级别:表示这条日志的严重性级别。进程或线程标识:表示日志来自哪个模块或脚本。 main 表示日志来自主模块。如果是其他文件会显示文件名。文件名和行号:记录日志消息的函数名和行号。日志消息:实际的日志内容,此外loguru支持使用颜色来区分不同的日志级别,使得日志输出更加直观.日志等级Loguru可以通过简单的函数调用来记录不同级别的日志,并自动处理日志的格式化和输出。这一特点可以让使用者专注于记录重要的信息,而不必关心日志的具体实现细节。Loguru支持的日志级别,按照从最低到最高严重性排序:TRACE: 最详细的日志信息,用于追踪代码执行过程。Loguru默认情况下使用DEBUG级别作为最低日志记录级别,而不是TRACE级别。这是因为TRACE级别会产生大量的日志信息。DEBUG: 用于记录详细的调试信息,通常只在开发过程中使用,以帮助诊断问题。INFO: 用于记录常规信息,比如程序的正常运行状态或一些关键的操作。SUCCESS: 通常用于记录操作成功的消息,比如任务完成或数据成功保存。WARNING: 用于记录可能不是错误,但需要注意或可能在未来导致问题的事件。ERROR: 用于记录错误,这些错误可能会影响程序的某些功能,但通常不会导致程序完全停止。CRITICAL: 用于记录非常严重的错误,这些错误可能会导致程序完全停止或数据丢失。from loguru import logger logger.debug("这是一条跟踪消息") logger.debug("这是一条调试信息") logger.info("这是一条普通信息") logger.success("操作成功完成") logger.warning("这是一条警告信息") logger.error("这是一条错误信息") logger.critical("这是一条严重错误信息")输出:2024-06-29 19:58:11.535 | DEBUG | __main__:<module>:3 - 这是一条跟踪消息 2024-06-29 19:58:11.536 | DEBUG | __main__:<module>:4 - 这是一条调试信息 2024-06-29 19:58:11.536 | INFO | __main__:<module>:5 - 这是一条普通信息 2024-06-29 19:58:11.537 | SUCCESS | __main__:<module>:6 - 操作成功完成 2024-06-29 19:58:11.537 | WARNING | __main__:<module>:7 - 这是一条警告信息 2024-06-29 19:58:11.538 | ERROR | __main__:<module>:8 - 这是一条错误信息 2024-06-29 19:58:11.538 | CRITICAL | __main__:<module>:9 - 这是一条严重错误信息1.2 日志配置在loguru中,add函数用于添加日志处理器。这个函数用于指定日志消息应该被发送到何处,例如控制台、文件或其他自定义的目的地。add函数主要参数介绍如下:sink: 定义日志消息的输出位置,可以是文件路径、标准输出(stdout)、标准错误(stderr,默认)或其他自定义的输出位置。format: 指定日志消息的格式,可以是简单的字符串,也可以是格式化字符串,支持各种字段插值。level: 设置处理程序处理的日志消息的最低级别。比如设置为DEBUG,则处理程序将处理所有级别的日志消息。filter: 可选参数,用于添加过滤器,根据特定的条件过滤掉不需要的日志消息。colorize: 布尔值,指定是否对日志消息进行着色处理,使日志在控制台中更易于区分。serialize: 布尔值,指定是否对日志消息进行序列化处理,通常与enqueue=True一起使用,以确保多线程安全。enqueue: 布尔值,指定是否将日志消息放入队列中处理,用于多线程应用中避免阻塞。backtrace: 布尔值或字符串,指定是否记录回溯信息,默认为False。diagnose: 布尔值,启用后,会在处理程序内部出现错误时记录诊断信息。rotation: 日志文件轮换的配置,支持按大小或时间进行日志文件的轮换。retention: 用于设置日志文件的保留时间。compression: 布尔值,指定是否对轮换后的日志文件进行压缩处理。from loguru import logger import sys # 终端显示不受该段代码设置 # 添加一个日志处理器,输出到文件 # 设置日志最低显示级别为INFO,format将设置sink中的内容 # sink链接的本地文件,如不存在则新建。如果存在则追写 logger.add(sink="myapp.log", level="INFO", format="{time:HH:mm:ss} | {message}| {level}") # debug结果不被显示到本地文件 logger.debug("这是一条调试信息") logger.info("这是一条普通信息")输出:2024-06-29 19:58:56.159 | DEBUG | __main__:<module>:11 - 这是一条调试信息 2024-06-29 19:58:56.159 | INFO | __main__:<module>:12 - 这是一条普通信息当连续两次调用 add 函数时,loguru 会将新的日志处理器添加到处理器列表中,而不是覆盖之前的处理器。这意味着所有添加的处理器都会接收到日志消息,并且按照它们被添加的顺序来处理这些消息。from loguru import logger logger.add(sink="myapp1.log", level="INFO") logger.add(sink="myapp2.log", level="INFO") # 会同时存入所有add添加日志处理器 logger.info("这是一条普通信息,存入myapp2")如果想删除所有已添加的日志处理器,loguru运行使用 logger.remove()方法不带任何参数来移除所有日志处理器。from loguru import logger import sys # 移除所有日志处理器(包括终端输出) logger.remove() logger.add(sink="myapp3.log", level="INFO", format="{time:HH:mm:ss} | {message}| {level}") logger.debug("这是一条调试信息存入myapp3") logger.info("这是一条普通信息存入myapp3")注意调用logger.remove()之后的所有日志将不会被记录,因为没有处理器了。from loguru import logger # 移除所有日志处理器(包括终端输出) logger.remove() # 没有输出 logger.info("这是一条普通信息存入myapp3")如果希望移除某些日志处理器,而不是从所有日志器中移除,代码如下:from loguru import logger # 移除默认终端logger,如果终端存在。 # logger.remove(0) # 添加多个文件处理器,enqueu设置异步日志记录 handler1 = logger.add("myapp1.log", enqueue=True) print(handler1) # handler_id是移除的处理器的唯一标识符 handler2 = logger.add("myapp2.log") # 记录一些日志 logger.info("这些信息会被记录到两个文件中") # 移除特定的文件处理器 logger.remove(handler1) # 现在只有myapp2.log 会记录日志 logger.info("这条信息只会记录在myapp2.log 中")如果想将日志输出到日志台,代码如下:from loguru import logger import sys logger.remove() # 移除默认输出 # 添加一个日志处理器,输出到控制台,使用自定义格式 logger.add( sink=sys.stdout, level="DEBUG", # green表示颜色 format="<green>{time:HH:mm}</green> <level>{message}</level>" ) # 注意终端显示会同步显示 logger.debug("这是一条调试信息") logger.info("这是一条普通信息")时间自定义 可以使用datatime库来自定义日志时间格式。from datetime import datetime from loguru import logger # 自定义时间格式 # time_format = "%Y-%m-%d %H:%M:%S,%f" # 包括微秒 time_format = "%H:%M:%S,%f" # 包括微秒但不含年月日 # 定义日志格式,使用 datetime.now().strftime() 来格式化时间 log_format = "{time:" + time_format + "} - {level} - {message}" logger.add("myapp.log", format=log_format, level="DEBUG") # 记录一条日志 logger.debug("这是一个带有微秒的测试日志")日志轮换from loguru import logger # 当文件大小达到100MB时创建新的日志文件,旧文件保留并重命名,用于防止单个日志文件变得过大。 logger.add("file_1.log", rotation="100 MB") # 每天中午12时创建新的日志文件,旧文件保留并重命名 logger.add("file_2.log", rotation="12:00") # 当日志文件存在超过一周时创建新的日志文件,旧文件保留并重命名 logger.add("file_3.log", rotation="1 week") # 设置日志文件保留10天 logger.add("file_4.log", retention="10 days") # 当文件大小达到100MB时创建新的日志文件,旧文件保留压缩为zip文件 logger.add('file_{time}.log', rotation="100 MB", compression='zip')1.3 进阶使用异常捕获 @logger.catch装饰器可以用来装饰my_function函数,并将这些异常信息记录到日志中。from loguru import logger logger.add(sink='myapp.log') @logger.catch def my_function(x, y): return x / y res = my_function(0,0)过滤 使用loguru库进行Python日志记录时,可以通过自定义的filter函数来筛选并记录特定的日志信息。此函数接收一个记录对象作为参数,根据日志消息内容(message)、级别(level)或其他日志属性,返回布尔值以决定是否记录该条日志。如果函数返回True,则日志被记录;若返回False,则忽略该日志。from loguru import logger # 定义一个过滤器函数 def my_filter(record): # 只记录包含 "第一" 的日志 return "第一" in record["message"] # 使用过滤器 logger.add("myapp.log", filter=my_filter) # 记录一些日志 logger.info("第一个记录") logger.info("第二个记录")此外可以结合bind方法进行过滤,bind方法用于向日志记录器添加额外的上下文信息。这些信息将被包含在每条日志消息中,但不会改变日志消息本身。如下所示:from loguru import logger def filter_user(record): return record["extra"].get("user") =="A" logger.add("myapp.log", filter=filter_user) # 绑定user logger.bind(user="A").info("来自A") logger.bind(user="B").info("来自B")原文出处:https://www.cnblogs.com/luohenyueji/p/18276299
-
git-stash用法小结 缘起今天在看一个bug,之前一个分支的版本是正常的,在新的分支上上加了很多日志没找到原因,希望回溯到之前的版本,确定下从哪个提交引入的问题,但是还不想把现在的修改提交,也不希望在Git上看到当前修改的版本(带有大量日志和调试信息)。因此呢,查查Git有没有提供类似功能,就找到了git stash的命令。综合下网上的介绍和资料,git stash(git储藏)可用于以下情形:发现有一个类是多余的,想删掉它又担心以后需要查看它的代码,想保存它但又不想增加一个脏的提交。这时就可以考虑git stash。使用git的时候,我们往往使用分支(branch)解决任务切换问题,例如,我们往往会建一个自己的分支去修改和调试代码, 如果别人或者自己发现原有的分支上有个不得不修改的bug,我们往往会把完成一半的代码commit提交到本地仓库,然后切换分支去修改bug,改好之后再切换回来。这样的话往往log上会有大量不必要的记录。其实如果我们不想提交完成一半或者不完善的代码,但是却不得不去修改一个紧急Bug,那么使用git stash就可以将你当前未提交到本地(和服务器)的代码推入到Git的栈中,这时候你的工作区间和上一次提交的内容是完全一样的,所以你可以放心的修Bug,等到修完Bug,提交到服务器上后,再使用git stash apply将以前一半的工作应用回来。经常有这样的事情发生,当你正在进行项目中某一部分的工作,里面的东西处于一个比较杂乱的状态,而你想转到其他分支上进行一些工作。问题是,你不想提交进行了一半的工作,否则以后你无法回到这个工作点。解决这个问题的办法就是git stash命令。储藏(stash)可以获取你工作目录的中间状态——也就是你修改过的被追踪的文件和暂存的变更——并将它保存到一个未完结变更的堆栈中,随时可以重新应用。git stash用法1. stash当前修改git stash会把所有未提交的修改(包括暂存的和非暂存的)都保存起来,用于后续恢复当前工作目录。比如下面的中间状态,通过git stash命令推送一个新的储藏,当前的工作目录就干净了。$ git status On branch master Changes to be committed: new file: style.css Changes not staged for commit: modified: index.html $ git stash Saved working directory and index state WIP on master: 5002d47 our new homepage HEAD is now at 5002d47 our new homepage $ git status On branch master nothing to commit, working tree clean 需要说明一点,stash是本地的,不会通过git push命令上传到git server上。实际应用中推荐给每个stash加一个message,用于记录版本,使用git stash save取代git stash命令。示例如下:$ git stash save "test-cmd-stash" Saved working directory and index state On autoswitch: test-cmd-stash HEAD 现在位于 296e8d4 remove unnecessary postion reset in onResume function $ git stash list stash@{0}: On autoswitch: test-cmd-stash2. 重新应用缓存的stash可以通过git stash pop命令恢复之前缓存的工作目录,输出如下:$ git status On branch master nothing to commit, working tree clean $ git stash pop On branch master Changes to be committed: new file: style.css Changes not staged for commit: modified: index.html Dropped refs/stash@{0} (32b3aa1d185dfe6d57b3c3cc3b32cbf3e380cc6a)这个指令将缓存堆栈中的第一个stash删除,并将对应修改应用到当前的工作目录下。你也可以使用git stash apply命令,将缓存堆栈中的stash多次应用到工作目录中,但并不删除stash拷贝。命令输出如下:$ git stash apply On branch master Changes to be committed: new file: style.css Changes not staged for commit: modified: index.html3. 查看现有stash可以使用git stash list命令,一个典型的输出如下:$ git stash list stash@{0}: WIP on master: 049d078 added the index file stash@{1}: WIP on master: c264051 Revert "added file_size" stash@{2}: WIP on master: 21d80a5 added number to log在使用git stash apply命令时可以通过名字指定使用哪个stash,默认使用最近的stash(即stash@{0})。4. 移除stash可以使用git stash drop命令,后面可以跟着stash名字。下面是一个示例:$ git stash list stash@{0}: WIP on master: 049d078 added the index file stash@{1}: WIP on master: c264051 Revert "added file_size" stash@{2}: WIP on master: 21d80a5 added number to log $ git stash drop stash@{0} Dropped stash@{0} (364e91f3f268f0900bc3ee613f9f733e82aaed43)或者使用git stash clear命令,删除所有缓存的stash。5. 查看指定stash的diff可以使用git stash show命令,后面可以跟着stash名字。示例如下:$ git stash show index.html | 1 + style.css | 3 +++ 2 files changed, 4 insertions(+)在该命令后面添加-p或--patch可以查看特定stash的全部diff,如下:$ git stash show -p diff --git a/style.css b/style.css new file mode 100644 index 0000000..d92368b --- /dev/null +++ b/style.css @@ -0,0 +1,3 @@ +* { + text-decoration: blink; +} diff --git a/index.html b/index.html index 9daeafb..ebdcbd2 100644 --- a/index.html +++ b/index.html @@ -1 +1,2 @@ +<link rel="stylesheet" href="style.css"/>6. 从stash创建分支如果你储藏了一些工作,暂时不去理会,然后继续在你储藏工作的分支上工作,你在重新应用工作时可能会碰到一些问题。如果尝试应用的变更是针对一个你那之后修改过的文件,你会碰到一个归并冲突并且必须去化解它。如果你想用更方便的方法来重新检验你储藏的变更,你可以运行 git stash branch,这会创建一个新的分支,检出你储藏工作时的所处的提交,重新应用你的工作,如果成功,将会丢弃储藏。$ git stash branch testchanges Switched to a new branch "testchanges" # On branch testchanges # Changes to be committed: # (use "git reset HEAD <file>..." to unstage) # # modified: index.html # # Changes not staged for commit: # (use "git add <file>..." to update what will be committed) # # modified: lib/simplegit.rb # Dropped refs/stash@{0} (f0dfc4d5dc332d1cee34a634182e168c4efc3359)这是一个很棒的捷径来恢复储藏的工作然后在新的分支上继续当时的工作。7. 暂存未跟踪或忽略的文件默认情况下,git stash会缓存下列文件:添加到暂存区的修改(staged changes)Git跟踪的但并未添加到暂存区的修改(unstaged changes)但不会缓存一下文件:在工作目录中新的文件(untracked files)被忽略的文件(ignored files)git stash命令提供了参数用于缓存上面两种类型的文件。使用-u或者--include-untracked可以stash untracked文件。使用-a或者--all命令可以stash当前目录下的所有修改。至于git stash的其他命令建议参考Git manual。小结git提供的工具很多,恰好用到就可以深入了解下。更方便的开发与工作的。原文出处:https://www.cnblogs.com/tocy/p/git-stash-reference.html
-
git stash Documentation 名称git-stash - 将变化藏在一个脏工作区中概述git stash list [<日志选项>] git stash show [-u | --include-untracked | --only-untracked] [<差异选项>] [<暂存>] git stash drop [-q | --quiet] [<暂存>] git stash pop [--index] [-q | --quiet] [<暂存>] git stash apply [--index] [-q | --quiet] [<暂存>] git stash branch <分支名> [<暂存>] git stash [push [-p | --patch] [-S | --staged] [-k | --[no-]keep-index] [-q | --quiet] [-u | --include-untracked] [-a | --all] [(-m | --message) <信息>] [--pathspec-from-file=<文件> [--pathspec-file-nul]] [--] [<路径规范>…]] git stash save [-p | --patch] [-S | --staged] [-k | --[no-]keep-index] [-q | --quiet] [-u | --include-untracked] [-a | --all] [<信息>] git stash clear git stash create [<信息>] git stash store [(-m | --message) <信息>] [-q | --quiet] <提交>描述当你想记录工作目录和索引的当前状态,但又想回到一个干净的工作目录时,请使用git stash。 该命令将你的本地修改保存起来,并将工作目录还原为与HEAD提交相匹配。这个命令所存储的修改可以用git stash list列出,用git stash show检查,用git stash apply恢复(可能是在不同的提交之上)。 在没有任何参数的情况下调用git stash等同于git stash push。 默认情况下,储藏库被列为 "WIP on branchname …",但你可以在创建储藏库时在命令行中给出更多描述性信息。你最近创建的储藏库被保存在refs/stash中;旧的储藏库可以在这个引用的引用日志中找到,并且可以使用通常的引用日志语法来命名(例如,stash@{0}是最近创建的储藏库,stash@{1}是它之前的储藏库,stash@{2.hours.ago}也是可以的)。也可以通过指定储藏库的索引来引用储藏库(例如,整数n等同于stash@{n})。命令push [-p|--patch] [-S|--staged] [-k|--[no-]keep-index] [-u|--include-untracked] [-a|--all] [-q|--quiet] [(-m|--message) <信息>] [--pathspec-from-file=<文件> [--pathspec-file-nul]] [--] [<路径规范>…]将你的本地修改保存到一个新的 "存储条目 "中,并将它们回滚到 HEAD(在工作区和索引中)。 <信息>部分是可选的,它给出了描述和储藏的状态。为了快速制作快照,你可以省略 "push"。 在这种模式下,非选项参数是不允许的,以防止拼写错误的子命令产生不需要的储藏条目。 这方面的两个例外是stash -p,它作为stash push -p的别名,以及为消除歧义允许在双连字符--之后的路径规范元素。save [-p|--patch] [-S|--staged] [-k|--[no-]keep-index] [-u|--include-untracked] [-a|--all] [-q|--quiet] [<信息>]该选项已被弃用,改为 "git stash push"。 它与 "stash push "的不同之处在于,它不能接受路径规范。 取而代之的是,所有非选项的参数都被串联起来,形成储藏消息。list [<日志选项>]列出你目前拥有的储藏目录。 每个 "储藏目录 "都列出了它的名字(例如,stash@{0}是最新的条目,stash@{1}是之前的条目,等等),条目产生时的分支名称,以及该条目所基于的提交的简短描述。stash@{0}: WIP on submit: 6ebd0e2...更新 git-stash 文档 stash@{1}: On master: 9cc0589... 添加 git-stash该命令采用适用于 git log 命令的选项来控制显示的内容和方式。参见 [git-log[1]](https://git-scm.com/docs/git-log/zh_HANS-CN) 。show [-u|--include-untracked|--only-untracked] [<diff选项>] [<储藏目录>]显示贮藏中记录的修改,作为贮藏内容与贮藏库条目首次创建时的提交之间的差异。 默认情况下,该命令显示diff统计,但它会接受 "git diff "已知的任何格式(例如,git stash show -p stash@{1}以补丁形式查看第二条最新条目)。 如果没有提供<diff选项>,默认行为将由stash.showStat和stash.showPatch配置变量给出。你也可以使用stash.showIncludeUntracked来设置是否默认启用--include-untracked`。pop [--index] [-q|--quiet] [<暂存>]从贮藏库列表中移除一个单一的贮藏状态,并将其应用于当前工作区状态之上,也就是做git stash push的逆向操作。工作目录必须与索引匹配。应用状态可能会因为冲突而失败;在这种情况下,它不会被从贮藏库列表中删除。你需要手动解决冲突,并在之后调用 git stash drop。apply [--index] [-q|--quiet] [<暂存>]和 pop 一样,但不从贮藏库列表中删除该状态。与pop不同,<贮藏项>可以是任何看起来像由stash push或stash create创建的提交。branch <分支名> [<贮藏项>]创建并检查一个名为 <分支名> 的新分支,从最初创建 <贮藏项> 的提交开始,将 <贮藏项> 中记录的修改应用到新的工作树和索引。 如果成功了,并且<贮藏项>是stash@{<版本>}形式的引用,那么它将删除<贮藏项>。如果你运行 git stash push 的分支发生了足够的变化,以至于 git stash apply 因冲突而失败,那么这就很有用。由于贮藏条目是在运行 git stash 时的 HEAD 提交之上应用的,它没有冲突地恢复了最初的贮藏状态。清除删除所有的贮藏条目。直接切断任何联系,而且可能无法恢复(可能的策略见下面的 "例子")。Drop [-q|--quiet] [<贮藏项>]从贮藏条目列表中删除一个单一的贮藏条目。create创建一个贮藏条目(这是一个普通的提交对象),并返回其对象名称,而不将其存储在引用命名空间的任何地方。 这是为了对脚本有用。 你可能不想用这个命令;可以看看前面的 "push"。保存将通过’git stash create'(这是一个悬空的合并提交)创建的特定贮藏库存储在贮藏库引用中,更新贮藏库参考文件。 这是为了对脚本有用。 这条命令可能不是你想要的;见上文"push"。选项-a--all这个选项只对push和save命令有效。所有被忽略的和未被追踪的文件也被贮藏起来,然后用git clean来清理。-u--include-untracked--no-include-untracked当与push和save命令一起使用时,所有未被追踪的文件也被贮藏起来,然后用git clean来清理。当与show命令一起使用时,显示贮藏库条目中未被追踪的文件作为差异的一部分。--only-untracked这个选项只对show命令有效。只显示贮藏库条目中未被追踪的文件作为差异的一部分。--index这个选项只对pop和apply命令有效。不仅试图恢复工作区的变化,而且恢复索引的变化。然而,这可能会在出现冲突时失败(这些冲突被存储在索引中,因此你不能再按原来的方式应用这些变化)。-k--keep-index--no-keep-index这个选项只对push和save命令有效。所有已经添加到索引中的变化都保持原样。-p--patch这个选项只对push和save命令有效。交互式地从 HEAD 和工作区之间的差异中选择要存储的内容。 藏匿条目的构造是这样的:它的索引状态与你仓库的索引状态相同,它的工作区只包含你交互选择的变化。 被选中的修改会从你的工作区中回滚。参见 [git-add[1]](https://git-scm.com/docs/git-add/zh_HANS-CN) 中的 '互动模式' 一节,了解如何操作--patch模式。选项 --patch 意味着 --keep-index。 你可以使用 --no-keep-index 来覆盖它。-S--staged这个选项只对push和save命令有效。只存放当前分阶段的修改。这类似于基本的git commit,只不过是将状态提交到贮藏室而不是当前分支。--patch选项要优先于这个选项。--pathspec-from-file=这个选项只对push命令有效。Pathspec在 <文件> 中传递,而不是在命令行参数中传递。如果 <文件> 正好是 -,则使用标准输入。路径规范元素由 LF 或 CR/LF 分隔。可以引用配置变量 core.quotePath 的路径规范元素(请参见 git-config[1])。另请参见 --pathspec-file-nul 和全局 --literal-pathspecs。--pathspec-file-nul这个选项只对push命令有效。只有在使用 --pathspec-from-file 选项时才有意义。指定路径元素用 NUL 字符分隔,所有其他字符都按字面意思(包括换行符和引号)表示。-q--quiet这个选项只对apply、drop、pop、push、save、store命令有效。静默,压制反馈信息。--这个选项只对push命令有效。为了消除歧义,将路径规范与选项分开。…这个选项只对push命令有效。新的贮藏条目只记录了符合路径规范文件的修改状态。 然后索引条目和工作区文件也被回滚到 HEAD 中的状态,只留下不符合路径规范的文件。更多细节请参见 [gitglossary[7]](https://git-scm.com/docs/gitglossary/zh_HANS-CN) 中的 路径规范 条目。这个选项只对apply、branch、drop、pop、show命令有效。一个形式为stash@{<版本>}的引用。如果没有给出<贮藏项>,则假定是最新的储藏库(即stash@{0})。讨论一个贮藏库条目被表示为一个提交,它的目录树记录了工作目录的状态,它的第一个父节点是创建该条目时在HEAD的提交。 第二个父节点的树记录了条目生成时索引的状态,它是HEAD提交的一个子节点。 祖先图看起来像这样: .----W / / -----H----I其中H是HEAD提交,I是记录索引状态的提交,W是记录工作区状态的提交。实例拉进一个脏目录树当你在做某件事的时候,你得知上游有一些变化可能与你正在做的事情有关。 当你的本地修改与上游的修改不冲突时,一个简单的`git pull’就可以让你继续前进。然而,在有些情况下,你的本地修改确实与上游修改有冲突,而git pull拒绝覆盖你的修改。 在这种情况下,你可以把你的进度保存起来,执行一次拉取,然后再解开,像这样:$ git pull ... 文件 foobar 不是最新的,无法合并。 $ git stash $ git pull $ git stash pop中断的工作流程当你正在做某件事的时候,你的老板来了,要求你立即修复某件事。 传统上,你会向一个临时分支提交,以储存你的修改,然后返回到你的原始分支进行紧急修复,就像这样:# ... 嗨骇害 ... $ git switch -c my_wip $ git commit -a -m "我待会还得写点东西" $ git switch master $ edit emergency fix $ git commit -a -m "速速修复BUG" $ git switch my_wip $ git reset --soft HEAD^ # ... 继续骇入 ...你可以用’git stash’来简化上述工作,像这样:# ... 嗨骇害 ... $ git stash $ edit emergency fix $ git commit -a -m "紧急修复" $ git stash pop # ... 继续骇入 ...部分测试提交当你想把工作区上的改动做两个或更多的提交,并且想在提交前测试每个改动时,你可以使用git stash push --keep-index:# ... 嗨骇害 ... $ git add --patch foo # 仅将第一部分添加到索引中 $ git stash push --keep-index # 将所有其他改动保存到储藏室中 $ edit/build/test first part $ git commit -m '第一个部分' # 提交完全测试过的改动 $ git stash pop # 准备处理所有其他改动 # ... 重复以上五个步骤,直到剩下一个提交... $ 编辑/构建/测试剩余部分 $ git commit foo -m '剩余部分'。保存不相关的变化供将来使用当你在进行大规模修改时,发现一些不相关的问题,你不想忘记修复,你可以进行修改,将其分阶段,然后使用 git stash push --staged 将其存放起来,以便将来使用。这类似于提交阶段性修改,只是提交的结果是在贮藏库而不是在当前分支。# ... 嗨骇害 ... $ git add --patch foo # 将不相关的改动添加到索引中 $ git stash push --staged # 将这些改动保存到储藏库中 # ... 嗨骇害, 完成当前改动 ... $ git commit -m '大规模测试' # 提交完全测试过的改动 $ git switch fixup-branch # 切换到另一个分支 $ git stash pop # 完成已保存更改的工作恢复被错误地清除/丢弃的贮藏库条目如果你错误地丢弃或清除了贮藏库条目,它们无法通过正常的安全机制恢复。 然而,你可以试试下面的咒语,以获得仍在你的版本库中,但无法到达的贮藏库条目列表:git fsck --unreachable | grep commit | cut -d -f3 | xargs git log --merges --no-walk --grep=WIP原文出处:https://git-scm.com/docs/git-stash/zh_HANS-CN
-
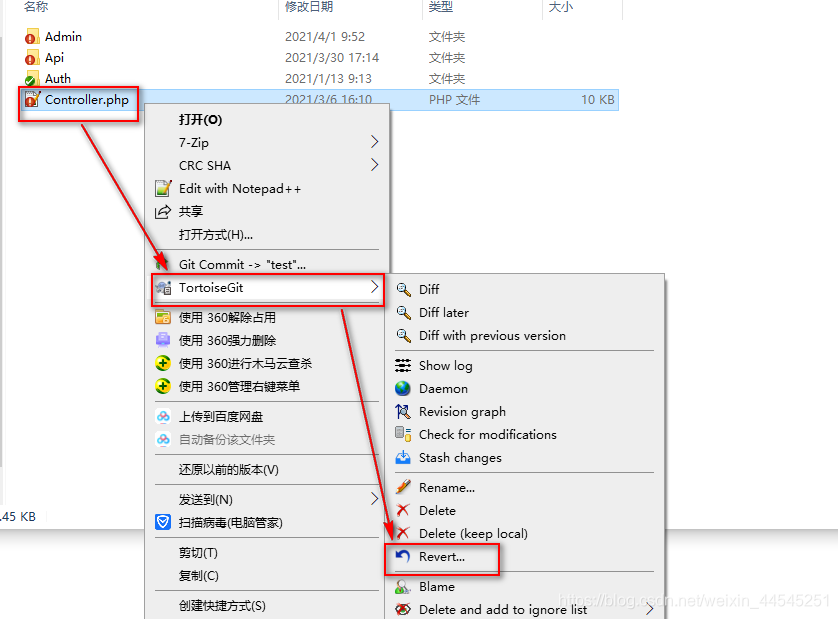
Git冲突:Please commit your changes or stash them before you merge 使用git pull来更新代码时,有时会遇到以下的问题:**error: Your local changes to the following files would be overwritten by merge:....phpPlease, commit your changes or stash them before you can merge.Aborting** 这个问题原因是其他人修改了某个文件并提交到版本库中去了,而你本地也修改了同一个,这时候你进行拉取就会出现冲突了,解决方法,原则是不要去更改别人已经提交的代码,如果确实要更改(不建议也不需要),请先跟当事人沟通方法一:放弃本地修改(此方法本地修改的代码会被丢弃,不可找回)git reset --hard git pullgit reset --hard:撤销工作区中所有未提交的修改内容,将暂存区与工作区都回到上一次版本,并删除之前的所有信息提交方法二:同样是放弃本地修改使用TortoiseGit(小乌龟),打开冲突文件所在目录,如下:方法三:使用git stashgit stash git pull git stash popgit stash:保存当前工作进度,能够将所有未提交的修改(工作区和暂存区)保存至堆栈中,用于后续恢复当前工作目录。也可以用git stash save,作用等同于git stash,区别是可以加一些注释git pull:这个应该不用说了吧!(把服务器仓库的更新拉到本地仓库中)git stash pop:可以把你刚才stash到本地栈中的代码pop到本地(也可以用git stash apply,区别:使用apply恢复,stash列表中的信息是会继续保留的,而使用pop恢复,会将stash列表中的信息进行删除。)git stash list:存储到本地栈顶以后,你可以使用git stash list 查看你本地存储的stash日志git stash clear: 清空Git栈,原来stash的节点都会被清除原文链接:https://blog.csdn.net/weixin_44545251/article/details/115366666
![[python] Python日志记录库loguru使用指北](https://blog.yiyunt.cn/usr/themes/Joe-master/assets/thumb/34.jpg)